 Up to Topics
Up to Topics Previous
PreviousAnalysis/Synthesis
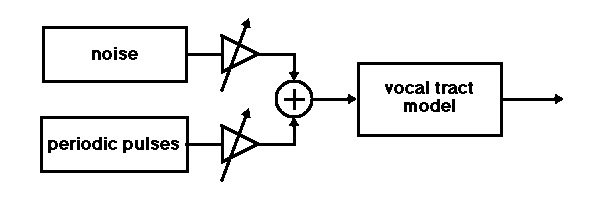
The Voder demonstrated the validity of Homer Dudley's model of speech generation by showing that an electromechanical device with relatively few controllable parameters could produce intelligible speech. His vocoder replaced the human operator with another electromechanical device that analyzed the speech, and hence was fully automatic. The combined analysis/synthesis device is the precursor of most speech coders today, including those used in digital cellular telephony. While modern speech coders use linear prediction in the analysis phase, Dudley's vocoder used a simpler spectral estimator, a bank of bandpass filters.
The rough structure of the synthesis side of the vocoder is shown below:
The vocoder is demonstrated with audio samples below. The audio is from an original Bell Labs recording of 1939. The speaker is alleged to be C. Voderson, although this seems unbelievable.
Introduction
The introduction to the vocoder itself has been processed by the vocoder, demonstrating reasonably good audio quality (by telephone standards, which emphasize intelligibility and speaker recognition over audio fidelity).
Comparison
Here, the vocoder output is compared to uncoded output (over a "public address system").
Unvoiced speech
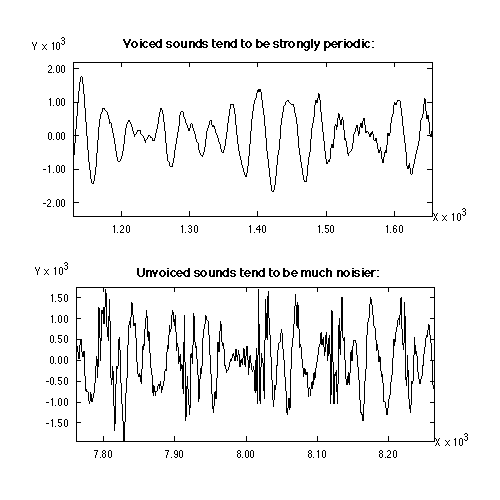
Whispered speech is generated by setting the vocoder as if all speech were unvoiced (input to the synthesis filter is only "hiss-type energy"). Below, a plot of voiced speech (top) is compared to a plot of unvoiced speech (bottom) in the time domain.
Voiced speech
Mechanical-sounding speech generated by setting the vocoder as if all speech were voiced (input to the synthesis filter is only "buzz-type energy").Monotone speech
Here, both voiced and unvoiced sounds are produced, but the voiced sounds are held at a constant pitch, yielding a monotone effect.Pitch modifications
Here, pitch is modified under the control of a hand dial.One octave lower
An octave is a factor of two in frequency. In this demonstration, the vocoder halves the pitch of the speaker.One octave higher
In this demonstration, the vocoder doubles the pitch of the speaker.Inflection
"Inflection" is the variations in pitch in speech. The vocoder can be set to reduce or increase the inflection without shifting the pitch up or down.Inflection manipulations on a song
In this demonstration, the inflection reduction and enhancement is demonstrated on a song.Reversing the inflection
In this demonstration, inflection is reversed. That is, when the pitch of the original speech would be rising, here it is falling, and vice versa.Special effects sounds
Here, the vocoder is used to synthesize non-speech sounds.Vibrato
Vibrato is a musical term for a rapid fluctuation in pitch. This illustration uses the vocoder to introduce vibrato into a singing voice signal.Jones family
In this demo, various of the above effects are combined to alter a single voice to play several roles in short skit.Combining two voices
Here, a voice is shifted in pitch by a frequency interval known to musicians as a major third. The shifted voice signal is combined with the original to achieve a harmonious effect.Combining three voices
Here, a voice is shifted in pitch by two frequency intervals to make what is known to musicians as a triad. The shifted voice signals are combined with the original to achieve a harmonious effect.Permuting the frequency channels
Here, the three lowest frequency channels are redirected in synthesis to the three middle channels at higher frequencies. The result is a nasal effect, with the low frequencies missing.Permuting the frequency channels
Here, the three middle frequency channels are redirected in synthesis to the three lowest channels. The result is a strange effect, with the middle frequencies missing.Complete Audio File
The entire audio for the above demonstrations is available in Sun Audio format (.au files) (8,3700k).
Professor Edward Lee's Home Page.