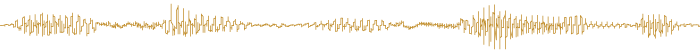
 Up to Topics
Up to Topics Next
NextSound
A continuous audio signal (a sound) is a function:
where the set Time represents an interval of time and the set Pressure represents air pressure. The human ear detects rapid changes in air pressure as sound when the changes occur in the range of about 30 to 20,000 Hertz (cycles per second). See the review of sets and functions, if necessary.
Listen to a speech signal, where your professor is saying "This is the sound of my voice":
This can be plotted as air pressure vs. time. Here is the first second of the speech signal, where air pressure is represented in arbitrary units (which happen to be integers in the computer):
A voice segment is a function of the form
The pressure Voice(t) assigned to any t ∈ [0, 1] is represented by the graph or waveform above. As with all signal plots on these pages, you can zoom in on the signal by clicking and dragging your mouse down and to the right. After zooming in, you can zoom out by clicking and dragging up and to the right, or by clicking on the "fill" button. Examine this plot carefully and see if you can identify the speech phonemes.
Notice, however, that the vertical axis does not directly represent pressure. In fact, it ranges over the possible values of 16-bit integers, which is Integers16 = {-32,768, ... , 32,767}. So the above graph more accurately represents the function
The audio hardware of the computer is responsible for converting members of the set Integers16 into air pressure.
This is still not quite right, however. The sound above is represented in the computer not as a continuous-time waveform, but rather as a list of numbers (8,000 numbers for every second of speech). Thus, a more accurate plot of the computer representation of a section of speech might be:
This plot shows 100 data points (samples). Since there are 8,000 samples per second, these 100 points represent 100/8,000 seconds, or 12.5 milliseconds of speech. Such a signal is said to be a discrete-time signal because it is defined only at discrete points in time. Formally, a discrete-time audio signal in the computer is a function
where the set DiscreteTime contains integers that index the discrete points of time. By contrast, a continuous-time signal is a function defined over a continuous interval of time (technically, a continuum in the Reals). The audio hardware of the computer is responsible for converting this function into a function of the form