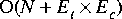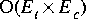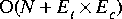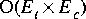






Cluster class in the Ptolemy kernel which scheduler writers can use directly or, if need be, derive specialized clustering classes. The older schedulers such as the BDF scheduler and the SDF loop schedulers have not been upgraded to use the new Cluster classes. Thus, the BDF and SDF schedulers should not be used as examples of how to do clustering in Ptolemy, but rather the hierarchical SDF parallel scheduler ($PTOLEMY/src/domains/cg/hierScheduler) can be used as a model. The HierScheduler in the current version of Ptolemy is a prototype of the hierarchical parallel scheduler detailed in [Pin95]. In addition, we have a specialized loop scheduler [Mur94] which also uses the new cluster facilities.The class
Cluster is derived from the DynamicGalaxy and as such manages its own memory. The Cluster classes use ClusterPorts which are derived from GalPort. The main difference between the ClusterPorts and GalPorts is that ClusterPorts maintain a farSidePort pointer. We need this change in ClusterPort in order to easily iterate over the Clusters at any level of the clustering hierarchy. A ClusterPort::farSidePort pointer will only be NULL if the ClusterPort is aliased to a Star PortHole connected at higher level of the clustering hierarchy.
Cluster instance and then invoking the Cluster::initializeForClustering method on the Galaxy whose internals we want to cluster. This top-level Galaxy will remain intact, but all internal Galaxies which pass the Cluster::flattenGalaxy test will be flattened and deleted. Thus any Scheduler and Target pointers to the top-level Galaxy will not need to be updated because they do not change. The necessary information from the user-specified hierarchy is preserved automatically with the aid of the Scope class detailed in section
6.5.
After the internals of the top-level Galaxy have been flattened, Clusters are constructed around each individual atomic Block. In that way, the scheduler writer can treat all the Blocks at each level (except the innermost level) as a Cluster. This property is maintained through any sequence of merge/absorb calls. An example initializeForClustering invocation is shown in figure
6-1, frames 1 and 2.
A facility for restoring the internal Ptolemy representation back to the original user-specified hierarchy is detailed in section 6.6.
6.4.2 Absorb and Merge
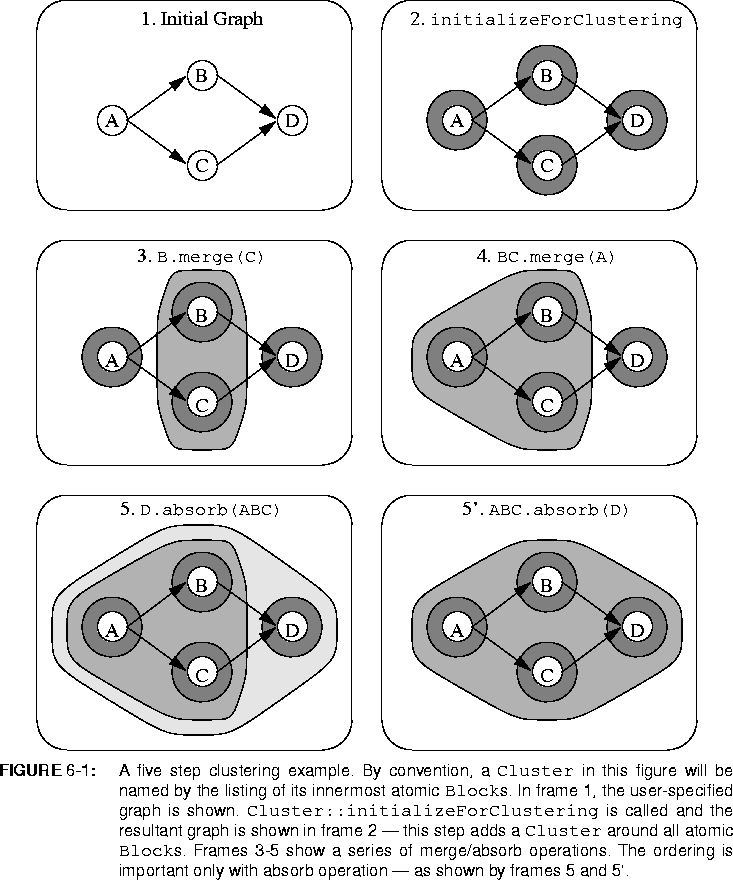
Cluster::merge and Cluster::absorb. Both of these methods can take up to two arguments. The first argument is the Cluster to absorb/merge and the second argument(optional) specifies whether or not to remove the absorbed or merged Cluster from the original parent Galaxy. Cluster::merge method takes the contents of the Cluster being merged and moves them into the Cluster pointed to by the this pointer. A merge operation is communicative. A series of merge steps is shown in figure
6-1 frames 3 and 4.
The Cluster::absorb method takes the Cluster being absorbed and moves it into the Cluster pointed to by the this pointer. Unlike merge, absorb is not communicative as shown in figure
6-1 frames 5 and 5'.
The absorbed or merged Cluster is removed from the original parent Galaxy by default when Cluster::merge or Cluster::absorb is called. We provide three ways to update the graph after a clustering operation with differing levels of efficiency. These methods are detailed in the table
6-1. We first list some variable definitions:
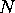
Clusters in the parent Galaxy
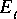
PortHoles in this Cluster
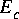
PortHoles in the Cluster to absorb or merge
Cluster iterator classes assume that all Blocks in the Galaxy being iterated on are Clusters. This property is TRUE assuming that the Galaxy (or one of its parent Galaxies) has been properly initialized (section
6.4.1) and merge/absorb have been the only functions that have modified the topology of the graph since the initialization. These iterators ignore pointers to invalid Clusters which have been left in the Galaxy using merge/absorb with the removeFlag set to FALSE (last two cases in table
6-1). The cluster iterators are listed in table
6-2.